本文共字,预计阅读时间。
文/清华五道口金融安全研究中心
2024年10月19日,2024金融街论坛年会成方金融科技论坛—“人工智能+金融创新”论坛在京举办。本次论坛由中国人民银行、北京市政府等主办,中国工商银行承办。在论坛的专家对话环节,中国银联、农业银行、建设银行、交通银行、邮储银行金融科技领域的专家代表,围绕“人工智能技术金融应用”主题进行了深入探讨。清华五道口金融安全研究中心人员在现场进行了采编,核心观点如下。
应用场景越来越广泛
当前银行业对“人工智能+金融创新”这一必然发展趋势已形成共识,人工智能,特别是生成式人工智能在银行业务领域的应用越来越广泛。在策略上,主要关注降成本、控风险和优化用户体验这三个关键点。在行动上,主要遵循先内后外、稳妥推进、持续投入的发展步骤。银行业在推动生成式人工智能应用落地方面也取得了显著成效。

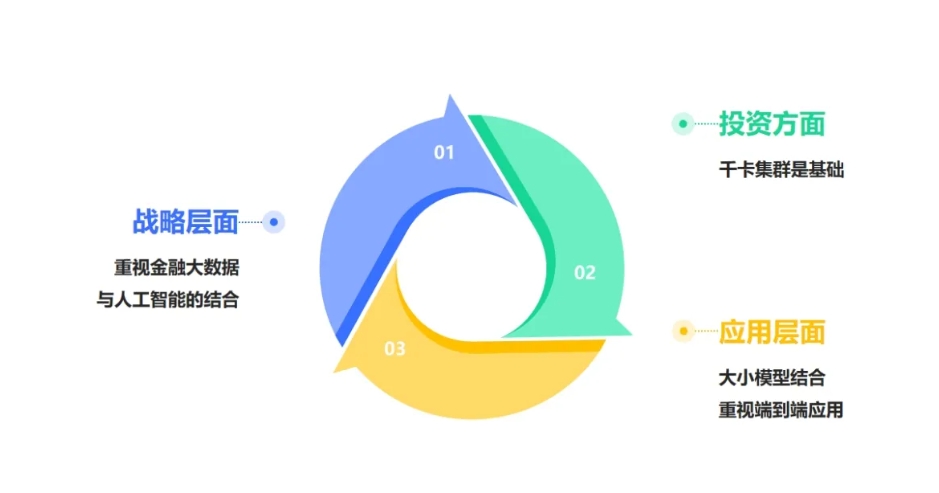
重视算力和端到端应用
在战略层面,通过人工智能利用好金融大数据是银行业“人工智能+金融创新”关注的重点。在具体投资方面,“大模型需要大算力,大算力需要大投入”是目前银行业人工智能应用发展需要关注的关键问题。对于算力的规划,既需要满足当下也要着眼未来,要做好算力的战略投资规划,例如需要建设千卡集群等。在应用层面,银行业比较重视端到端的应用,会采用大小模型有机结合的方式以实现最优化的应用效果。
数据质量和数据标注很关键
金融人工智能训练涉及到大量非结构化的数据,而非结构化的数据需要人工标注。将高价值的非结构化金融数据转化为有效的数据集,是一个非常繁重的工作。
一是源头上,随着多模态金融大模型的发展,对数据资源的丰富性和多样性的需求日益增长。因此,持续丰富和扩展数据来源变得尤为重要。
二是组织上,加强同业合作。在数据脱敏和统一标准的前提下,共同整合和共享数据资源,建立高质量的行业数据集。
三是架构上,对银行系统的数据架构进行调整。与传统的数据使用方式相比,面向人工智能的数据应用在数据类型、数据格式以及数据处理和标注等加工流程上存在显著差异。因此,从架构层面进行调整是实现数据高效流通、存储、处理和标注的关键前提,以确保大模型能够充分利用数据资源,从而提升模型训练的准确性和效率。
四是制度上,需要建立配套的规章制度。由于传统的数据处理模式(如存储和分发)并不适用于当前非结构化数据大量涌现的知识库建设需求,因此有必要制定新的数据治理规范,构建面向人工智能应用的配套制度体系。
五是执行上,可开展“作业级”标注。如果组织专门的人员进行数据标注,会花费大量的时间,因此有银行提出,开展“作业级”标注——在作业的过程中把数据标注出来,把所需要的知识沉淀下来。同时,有银行提出,可以采取“场景式”“专班制”柔性团队和“总分行结合,内外部联动”的方式方法来开展数据标注工作。
六是平台上,建立工具化平台。例如通过建立样本库、评测数据集、数据标注平台等加速大模型所需要的数据沉淀、标注和数据集的制作工作。

依然需要程序员
人工智能自动代码生成是当前的热点。然而,根据参与对话的银行金融科技领域专家代表的反馈,目前在金融科技领域,人工智能生成的代码大部分依然无法直接使用(具体比例因研发场景而异)。此外,大模型目前仍难以深入理解银行业的复杂业务逻辑。因此,当前银行业人工智能相关应用研发仍然离不开人类程序员的参与。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号