本文共字,预计阅读时间。
内幕交易是金融市场的一个重要特征,各种学术文献都试图对此进行解释。例如,知情投资者有助于保持证券价格接近基本价值,因此对于市场效率理论至关重要。
然而,内幕交易很难凭经验来识别,因为投资者做出决策的信息集无法直接观察到,而且知情的投资者通常隐藏在不知情的投资订单流背后。为了克服这些挑战,文献开发了几种基于理论的内幕交易和/或逆向选择措施。其中最广泛应用于实证金融、经济学和会计领域的著名指标包括价格影响、买卖价差以及内幕交易概率。但最近的研究表明,这些措施在捕获已实现的内幕交易方面表现不佳。
来自波士顿学院的Vincent Bogousslavsky、卡罗尔管理学院的Vyacheslav Fos以及密歇根州立大学的Dmitriy Muravyev于2024年2月在金融学国际顶刊《The Journal Of Finance》发表论文“Informed Trading Intensity”。
本文中,作者们介绍了一种新颖的数据驱动方法来构建实现内幕交易的衡量标准。具体来说,作者根据内幕交易数据训练梯度提升树(XGB)算法,对交易日进行分类,识别当日是否应该划分为“有内幕交易”一类中。在这个标准分类问题下,内幕交易的每日指标是通过一组与流动性、回报、波动性和交易量相关的当日变量来预测的。这一过程产生了一种新的内幕交易衡量标准,文章将其称为内幕交易强度(ITI)。ITI 结合了两个关键要素:内幕交易数据和机器学习 (ML) 方法。
一、研究数据
文章利用机器学习方法构造内幕交易强度指标(ITI)可以总结为如下过程:在每一个交易日,知情者均有可能进行内幕交易,而内幕交易的方式与普通投资者组成的“普通交易或噪音交易”是存在显著不同的,所以导致比如价差、流动性、价格冲击等日度特征在普通交易日与存在内幕交易的交易日出现不同(实际上这也是现存文献中构造的内幕交易强度指标的思路)。
进一步的,虽然没有哪一种指标能够严格地识别出内幕交易存在的交易日,但可以“近似观测”到内幕交易存在的时期。这样就可以将“利用日度交易特征计算内幕交易强度指标”的问题转化为“利用机器学习识别内幕交易日特征结构”的监督学习问题。
其中,关键是找到合适的标准使得机器学习算法“近似观测”到内幕交易存在的交易日。关于这一点,文章主要使用的是按照美国证券交易委员会要求的13D披露文件进行内幕交易日识别。在美国资本市场中,任一个人或群体获取某股票超过5%市值时,会被要求提供13D披露文件。作者认为,大幅增持某股票的投资者会认为自己有能力提升目标股票的价值,或是掌握目标股票的私有信息。而这一过程是逐步发生的,即该投资者逐渐购入目标股票,直至超过13D文件所规定的披露限额,并最终填写13D披露文件。在该文件中,投资者被要求报告填写表格前60天的所有交易情况。至此,这六十天内被该投资者交易过的股票都可以“近似”视作内幕交易日。
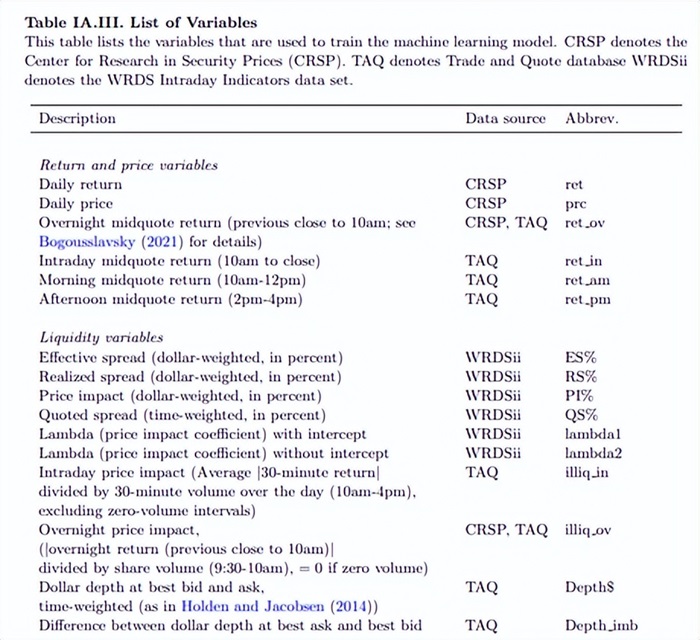
完成内幕交易日的“观测”后,作者进一步选择了41个日度交易指标作为该交易日的“特征”。下表为部分特征变量。
二、内幕交易强度指标(ITI)构造
完成前述变量整理后,作者正式开始使用机器学习方法构造内幕交易强度指标。作者将 Schedule 13D 事件分成训练集和测试集,当在训练集确定机器学习模型中的超参数与参数后,文章在测试集中预测每一交易日是否存在内幕交易。具体地,作者使用XGBoost算法以及其他机器学习应用中的标准方法,具体详细模型构建步骤可参读原文第二章。
最终,机器学习模型可以根据每一交易日的特征(41个日度交易指标)对该交易日进行判定,判定其是否为内幕交易日,并将其作为本文的核心指标,即数据驱动并基于机器学习算法的内幕交易强度指标(ITI)。
三、ITI的经济性质与应用
完成ITI指标构造后,作者首先检验了该指标的性质。作者关心该指标是否能够识别13D文件中报告的60个交易日,以及这些交易日内的交易量。
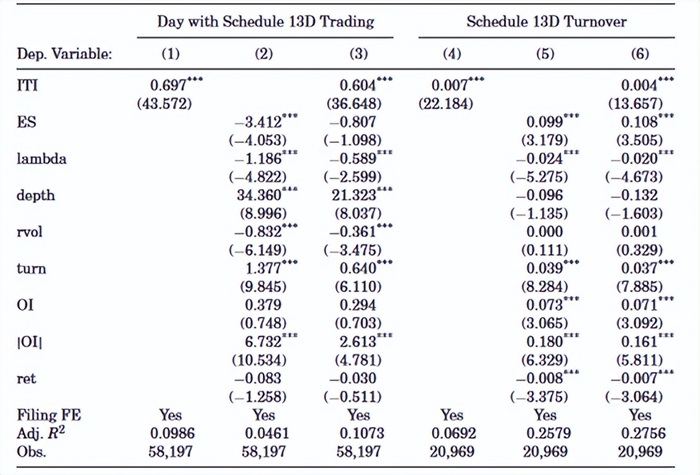
上表列(1)-(3)显示ITI以及其他若干交易指标均显著识别了13D文件中所记载的“内幕交易日”。并且文章发现,ITI指标能单独解释13D文件中交易日的9.8%、而其他若干交易指标的联合解释力则仅有一半(4.6%),这充分表明了机器学习算法通过对指标进行组合与交互,能够捕捉普通交易指标无法捕捉的信息。列(4)-(6)则显示,ITI 与 13D 交易日内的股票交易量呈显著正相关。当控制常见流动性指标时,ITI 与 13D 交易日内的股票交易量之间的正相关关系仍然存在。总之,上表显示 ITI 捕获了标准流动性指标未检测到的内幕交易。
通常使用机器学习构造指标的研究很难解释其方法的有效性。为了解决这个问题,作者确定了 ITI 最重要的组成部分。具体地,文章将模型的41个特征分为四组,即流动性、回报、波动性和交易量变量。然后,作者每次仅使用变量的一个子集来训练模型来预测 Schedule 13D 交易。因此,文章获得了仅基于四个子集中一个的特定 ITI 变量。
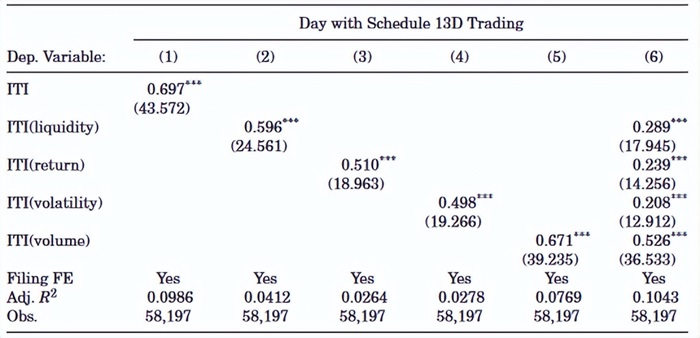
上表报告了基于特定特征集构造的ITI在识别13D文件中交易日的结果。相比其他指标,回报率和波动率变量ITI的解释力较低。就其本身而言,价差、价格影响和深度等流动性变量的样本外解释力大约是由所有变量构建的 ITI 的一半。然而,第 (6) 列显示,没有任何一个特征集的解释力能完全被另一特征集所包含。
接下来,文章又借助二叉树来研究变量交互如何影响 ITI指标。虽然ITI 由复杂的机器学习模型所产生,但其过程可以通过简单的三层二叉树来近似。
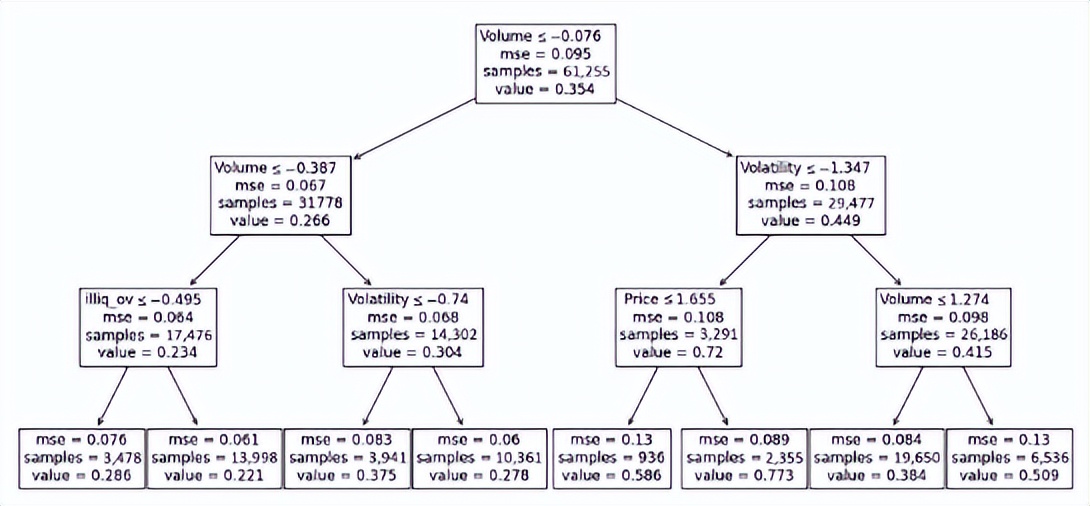
上图显示了对应的三层二叉树。该树旨在捕捉 ITI 最重要的属性,并解释约三分之一的 ITI 变化。它产生了两个重要结论。
首先,变量进入树的频率以及它在树中的高度(是否靠近上方的根节点)可以帮助评估其重要性。图中显示交易量进入树三次,包括在最上方的根节点。波动性和流动性则决定了第二层次。
其次,如果交易量高但波动性低,则 ITI 特别高。同样,如果交易量低且流动性不足,ITI 就会特别低。这说明了 ITI 如何考虑输入变量之间的各种非线性和相互作用。
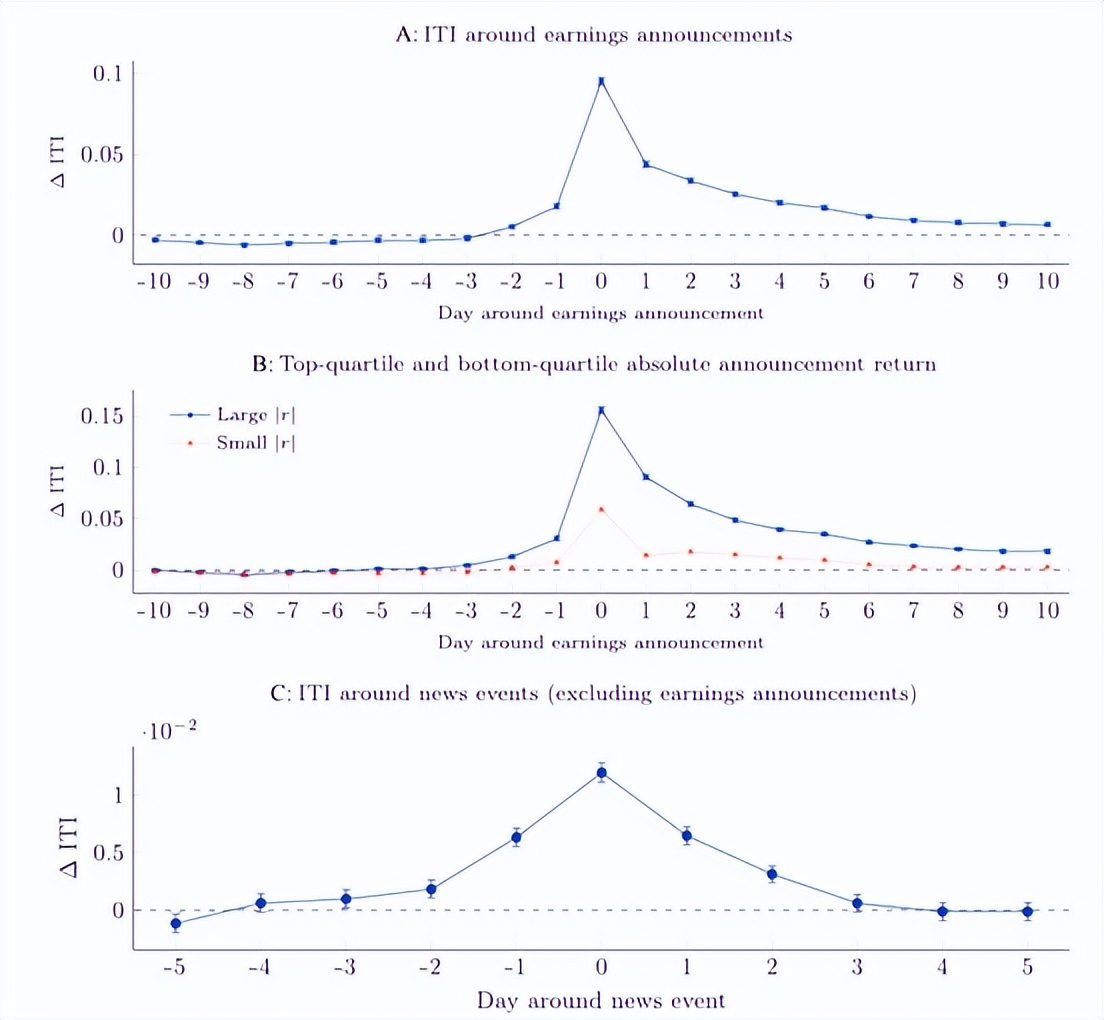
随后,作者研究公司披露信息前 ITI 的动态。从上图中可以看出,ITI 在收益公布前两天在统计上较高,在公布当天飙升,然后在几天内保持高位。这样的结果表示公共新闻的披露增加了投资者之间的信息不对称,因为一些投资者比其他投资者能够更好地处理新信息,因此推动了ITI上升。
最后,文章通过检查 ITI 和未来股票收益之间的关系来提供资产定价方面的应用。下表显示如果前一周已实现的内幕交易较高,则下个月该股票会出现较高的已实现回报。而且ITI预测回报的能力不受其他预测变量控制后的影响。这些结果显示,ITI 与未来收益正相关的结果与内幕交易风险理论是一致的,即内幕交易者的确存在推高股价的能力,或是掌握了未来该股票上涨的私人信息。

四、结论
在本文中,作者通过直接学习内幕交易数据来开发一种新的内幕交易衡量标准。通过考虑一个机器学习中的标准分类问题,文章结合股票日度交易指标和机器学习算法来识别内幕交易存在的交易日。作者表明,ITI 可以显著预测样本外内幕交易。ITI 会在盈利公告、并购公告和计划外新闻发布之前上涨。这些结果都验证了作者所构造的ITI的合理性。
文章证明,数据驱动的指标构建方法可以揭示内幕交易的经济学原理。并且ITI 可应用于如资产定价的许多场景。文章表明,ITI 的增加与横截面中未来较高的月度回报相关。本文的主要贡献在于,数据驱动的机器学习方法与内幕交易数据相结合,可以生成有效的内幕交易衡量标准,并提高对内幕交易的经济学理解。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号