本文共字,预计阅读时间。
自然语言处理和机器学习的快速发展催生了生成式大语言模型(GLLMs),例如OpenAI的ChatGPT和GPT-4模型。这类新型模型在分析文本数据的会计研究中具有巨大的潜力。
它们具备与人类类似的对文本的理解和生成能力,可以适应多种任务,轻松解决文本分类、翻译、摘要生成等问题。GLLMs的指令提示(prompt)使用方式简单。由于采用先进的机器学习技术,这些模型具备极高的可扩展性、快速的推理速度和低成本的优势。
虽然GLLMs功能强大,但它们也存在局限性,并带来新的挑战,需要谨慎审查。
本文的叙述参考华盛顿大学助理教授Ties de Kok在2024年3月完成的工作论文《ChatGPT for Textual Analysis? How to use Generative LLMs in Accounting Research》,该论文旨在为研究人员、审稿人和编辑提供如何在学术研究中有效使用和评估 GLLMs的建议。
文章概述
GLLMs是一类用于处理和生成文本的模型,类似于功能强大的自动补全工具。生成式预训练变换器(Generative Pre-trained Transformers,GPT)模型是最常见的一类GLLM。GLLMs的通用能力还使它们可以在无需或仅需少量训练数据的情况下完成许多任务,从而节省大量时间和资源。
例如,Hassan等人(2019)通过在庞大的财务电话会议数据集上训练一个算法,识别其中的政治风险相关内容。要实现这一目标是一个具有挑战性且耗时的任务。相比之下,最先进的GLLM如GPT-4可以直接解决这个问题(即“零样本zero-shot”),只需给它展示会议片段,并询问它是否涉及政治风险,如下图所示。较小的模型,如GPT-3或Llama2,通过适当的指令或训练也能获得类似的效果。
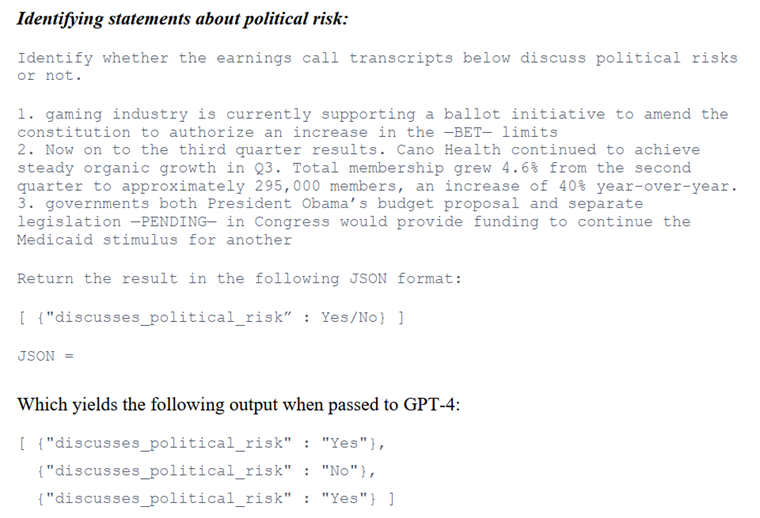
此外,GLLMs的规模使其具备一定的推理能力和对世界知识的理解能力,帮助它们解决难以自动化的问题。
总而言之,GLLMs可以帮助研究人员更轻松地分析文本数据,并研究新颖的论题。
尽管GLLMs功能强大,但它们也存在局限性并带来了新的挑战。GLLMs的自然语言特性使得它们看起来像一个有能力的人类在工作。然而,即使是最好的GPT模型也会出错,并且不能保证给出有意义的回答,特别是在直接使用的情况下。我们需要像对待其他机器学习方法一样,仔细评估其建构效度(construct validity)。此外,GLLMs的规模庞大,可能导致其运行速度较慢、成本高且难以控制。为克服这些限制,充分发挥GLLMs的潜力,需要以新的方式工作和思考。
然而,GLLMs的迅速普及伴随着缺乏关于如何在学术研究中使用这些模型的指导。这篇工作论文提供了相关介绍(基本原理以及和其他方法的比较)、应用框架、案例研究和细致的讨论,以帮助研究人员在项目中有效采用和评估GLLMs。这里我们将暂时跳过技术层面的相关内容,主要概述第一和最后一部分。
生成式大语言模型
GLLMs是一类能够处理和生成自然语言的机器学习模型,最著名的例子是OpenAI的ChatGPT:你向ChatGPT提问,它会给你一个答案。
GLLMs的关键创新是其生成能力,其任务是根据前面的词元预测(即生成)下一个词元,类似于打字时的自动补全。
词元(token)表示一个词、部分词或一个字符。例如,ChatGPT会将文本“Baseball is fun!”分解为词元:“Base”、“ball”、“ is”、“ fun”、“!”。GLLM的初始输入被称为提示(prompt),生成的结果称为补全(completion)。提示和补全都是词元的集合,模型会逐一预测补全中的每个词元。
专注于GPT模型,有许多不同的实现版本,例如ChatGPT、GPT-3、GPT-4、Gemini(Bard)、Claude、(Code)Llama2、CodeLlama和Phi-2等。这些模型之间的主要区别在于它们的参数规模、微调方式和可用性。
参数规模:决定了模型开箱即用的能力,但会以成本和速度为代价。
微调方式:决定了模型的响应方式以及模型擅长的任务类型。例如:ChatGPT模型经过微调,能够像人类助理一样响应指令;CodeLlama经过微调,专门用于生成代码。
可用性:决定了模型是可本地运行,还是只能通过第三方服务访问。
与BERT的比较
两种最著名的大语言模型是GPT和BERT。它们都是利用Transformer架构及其迁移学习能力的文本分析方法。
BERT模型作为更广泛的机器学习管道的一部分,是一个强大的构建模块。例如,Huang等人(2023)使用BERT模型来表示财务文档,然后将其输入到标准的机器学习分类器中,以进行情感分类。
与之相比,GLLMs是独立的,给它提供一个自然语言提示,模型生成补全内容,研究人员通过解析该补全来获取结论。例如,Lopez-Lira和Tang(2023)通过向ChatGPT展示新闻标题并询问“这个标题对<公司>的股价是好是坏?如果是好消息,请回答YES;如果是坏消息,请回答NO;如果不确定,请回答UNKNOWN”,从而对新闻情感进行分类。他们随后解析ChatGPT的回答,以确定情感分数。

借鉴网上的一个类比:BERT预训练任务类似完形填空,模型知道两边的词,预测中间的词。GPT类似阅读理解,模型知道问题,预测答案。

在小规模到中等规模的复杂文本分析问题上,GPT方法非常适用,而对于简单且大规模的问题,BERT方法更合适。GPT和BERT并不相互排斥,将它们结合起来有时可以获得两者的最佳优势。例如,GPT-4可以以低成本创建小规模但高质量的训练数据集,然后用于训练BERT,从而更便宜、更快速地扩展到大量文档。
与其他文本分析方法的比较
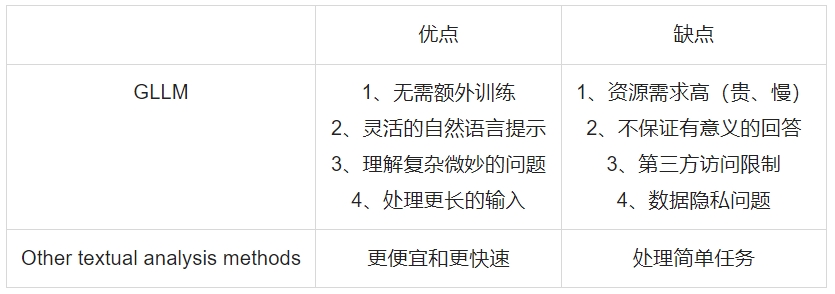
GLLMs在解决复杂的文本分析任务上具有显著优势,尤其是无需额外训练的灵活性和处理长文本的能力。然而,它们的成本、速度和数据隐私问题是需要研究人员权衡的重要因素。此外,GLLMs模型的回答乍看之下可能很好,但在验证之前应保持谨慎。
与人工编码的比较
GLLMs的强大功能和开箱即用的能力使其成为人工编码的潜在替代方案。对于相同任务,GLLM比人工编码更便宜、更快,且提供更一致的结果。GLLMs还能记忆和回忆大量信息,展现超越人类的能力。
然而,GLLMs不能保证与人工编码等效的结果。研究助理(RAs)的优势在于灵活性、推理能力和激励机制。一个激励充分的RA通常只需最少的指导就能提供高质量输出,而GLLM可能需要提示工程或微调才能达到相同效果。因此,对于小样本的复杂任务,人工编码更适合。
领域知识也是限制。GLLMs通常需要通过明确的例子学习领域知识,而这些例子可能难以获得或构建。例如,Hail等人(2018)通过人工编码区分道德上错误和法律上错误的会计丑闻,但向GLLM解释道德错误的含义具有挑战性。
讨论
在使用GLLMs进行研究时,研究人员需要关注几个关键问题,包括潜在的训练数据偏见、来源不确定性、近期事件的遗漏、可重复性挑战、数据隐私和版权风险。这些挑战要求研究人员在应用GLLMs时应谨慎对待。
(1)训练数据偏见
潜在影响:应用模型时可能会重现训练数据中的偏见。例如,与人工生成的职位信息相比,ChatGPT生成的职位信息包容性较低,在性别等方面存在明显偏见。
缓解措施:研究人员需要评估输出结果是否存在偏见,并通过提示设计或微调来减轻这些问题。
(2)来源问题
潜在影响:由于数据集很大,很难确切知道模型在生成时依赖的具体信息来源,这使得归因变得困难,同时模型行为难以预测。
缓解措施:通过提示或微调向模型提供重要信息。
(3)近期事件遗漏
潜在影响:GLLMs的训练数据只包含某一时间点之前的历史数据,任何在训练样本外的事件或变化都不会反映在模型输出中。
缓解措施:研究人员必须考虑这些局限性,并在解释结果时通过提示或使用最新数据对模型进行微调来弥补这些不足。
(4)可重复性挑战
潜在影响:相同提示的输出在不同模型、同一模型的不同版本之间,甚至在不同生成之间都可能存在显著差异。此外,第三方提供商可能随时更改或撤销模型。这些依赖带来了复制上的挑战。
缓解措施:避免依赖第三方API,尽量使用可以存储和本地运行的GLLM;始终备份原始提示和补全内容;尽量使生成过程确定性;保持透明和共享代码。
(5)数据隐私和版权风险
潜在影响:研究人员使用GLLMs时,需谨慎将数据共享。API提供商可能会利用用户提供的提示和生成内容来改进和重新训练他们的模型。这种做法可能导致敏感信息在未来的GLLMs输出中被无意披露,从而引发隐私泄露和版权侵犯的问题。
缓解措施:在不允许或不适宜分享数据的情况下,应避免使用第三方API,特别是当服务条款中明确指出提供商会使用这些数据作为训练材料时。
写作
GLLMs在写作中主要面临归因和事实准确性问题。例如,Bhattacharyya等人(2023)发现,ChatGPT生成的医学参考文献只有7%是真实且准确的。GLLMs可辅助校对或编辑学术写作,但研究人员应核查输出内容的准确性,避免错误归因。
编程
GLLMs是有效的编写和调试工具,但在应对复杂或特定任务时表现不佳。研究人员应验证代码的准确性,避免使用不能理解的代码。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号