本文共字,预计阅读时间。
为了传播金融创新典范,推进金融供给侧结构性改革,推动金融业服务实体经济,以及促进实现经济高质量、发展的目的,由北京市地方金融监督管理局指导,清华大学五道口金融学院、清华大学金融科技研究院主办,未央网承办推出“首都金融创新与发展”公开课,邀请金融行业嘉宾分享金融项目的创新模式,以及对行业未来发展前景的深度思考。
在首都金融创新与发展公开课的第四模块“金融科技创新与赋能”中,我们非常荣幸邀请到了阿博茨科技联合创始人余宙做客直播间,带来《人工智能在金融行业的虚与实》主题分享。以下整理来自嘉宾分享实录:
人工智能的本质是人与机器人逐渐融合而不是替代
人工智能的发展分为四个阶段,分别是计算智能、感知智能、认知智能和通用智能。其中感知智能是现在技术上最普及的,主要通过深度学习和神经网络使机器的进步更快,在某些领域达到甚至是超越人的水平。其应用场景包括人机接口(比如手写识别、刷脸支付),辅助人类(比如辅助医生对ct和病例进行识别),替代人类(比如语音合成文本),以及超越人类,比如在天气预报、无人驾驶等需要处理大量数据的领域,AI凭借其惊人的处理速度和规模效应可以更好地完成人的工作。而认知智能是指不仅能读懂理解还会思考,目前它还处于发展阶段。而对于通用智能,现在无论是技术还是应用场景都这种类似人类思维的阶段。
在目前人工智能的发展阶段,语言理解是很关键的一环,即对知识的掌握和运用能力。自然语言理解可以分成语音理解、知识表达、智能问答、联想推理和自主学习五个部分,其中语音理解是把语音拆成不同的字句段篇去逐字逐句逐个篇章地理解;知识表达是使机器以人能理解的方式表达,比如知识图谱;智能问答在人工智能领域实际上已经趋于成熟,这得益于有大量的历史训练样本可供学习;在联想推理和自主学习上,科技还没有太多实质性进展。
数据对AI的发展也非常重要,目前的核心问题是数据的失真效应、质量问题和长尾问题。对失真问题,所谓“谎言重复1000遍会变成真理”,实际上在人工智能尤其是用深度学习进行大样本数据训练时,因为机器按照提供的样本数据学习,很可能产生这种结果。因此训练数据集不透明时就容易出现“数据改变信仰”的情况。对数据质量,机器训练时都需要10万甚至100万的数据样本,并且数据被清晰标注,才能表现良好。尤其在迁移学习中,标注样本不足会经常产生一些很低级的错误。对长尾问题,是指用过往回撤的数据验证模型效果很好,但一旦出现黑天鹅事件,对未来预测的效果非常差。所以数据训练中高质量的数据是机器学习继续发展的关键之一。
另一个挑战是人工智能黑箱,深度学习的本质是依靠强大的算力在海量数据上做概率统计,通过发现数据中重复出现的模式来得出结论,但无法证明和解释这些模式和结论之间充分必要性,被人认为是暴力破解的方式。所以在实际运用过程中,尤其涉及到比如金融推理、判断决策等场景,还不敢使用机器得出的一些信息。
因此,可以看出AI在应用场景中并没有预计的成熟,无法能够在所有层面上取代人类,更多是处理一些相对确定的工作,在特定的垂直细分领域取代没有创造力的工作。其关键在于找到AI的优势,是海量的数据处理能力,从而发现其能够超越人类能力的领域。
人工智能的落地
人工智能如果要落地,首先会冲击数据密集、钱多的行业。首先如上文所说,数据优质且多才能使深度学习有足够的训练样本。第二点“钱多”是因为AI行业无论是人才招聘还是设备购买都离不开真金白银的支撑,而且也有很多资本看好其市场前景,它的融资规模在过去几年增长都很快。这也是人工智能最先在金融领域落地的依据,金融行业本身是数字游戏,尤其是二级市场,有很多公开数据;并且金融行业资本充足,也愿意为此付出更多预算。所以在信用评级、资产管理,量化投资和保险等金融领域很多独角兽公司。
对于商业模式,AI面临to B or to C的问题,由于上述人工智能在现阶段的挑战和问题,比如十分依赖人编写的算法、无法准确理解人类情感、对数据质量要求高等,现在人工智能更多还是面向企业落地业务服务。因为企业的业务场景垂直具体,内部存在大量相同岗位的工种,而不同于C端分散、个性化的业务场景。此外,企业经过多年运营沉淀下大量的相同类型的数据,并且企业规模越大,沉淀的数据越多,运用AI提升效率、降低成本的收益就越大。具体选择模式时,还需要注意四点:第一是尽可能选择相对标准的场景,从而降低销货成本;第二是选择大规模、低复杂度的场景,比如审核、数据清理、转录等,而不是一些开放域;第三是控制不同客户类型的成本,确保在不同的客户校准同样的模型时,降低实施部署成本;第四是要建立混合型业务,即在同一种能力下,提高服务能力。
人工智能尽管是软件和技术的出身,但在最终落地时可能趋向服务业特点。首先,AI模型所需的计算资源成本巨大,需要转嫁给供应商承担。第二是算法的进化一定离不开人,无法百分百智能,只有提供可持续的人的服务,才能让算法保持较高的精度。并且,高达40%-50%的功能属于长尾,因此解决边界情况的单位成本很高。此外,算法相同、技术开源和数据开放导致AI公司的技术护城河比预期浅,所以AI公司在构建核心竞争力时,能把技术能力、做应用的能力、获客能力和控制成本的能力聚集起来十分重要。
人工智能赋能金融场景
根据gigamo的统计,当前每天产生数据2.5×260,预计2020年每天产生数据将达到44 44×270,相当于1万GB,处于数据大爆炸时代,而这些数据如果不经过处理就无法变成资产,还会占用内存等大量资源。在金融行业,无论是一级市场还是二级市场,无论银行、保险还是基金,都有一个工作流程是收集数据,抽取精华,对数据进行搬运填报,最后进行可视化生成报告或图表,为决策提供依据。而前面可能有90%都属于体力活,意义不大但无可避免,所以提出“数据工厂”的概念来替代这些工作,下面是整体的示意图。
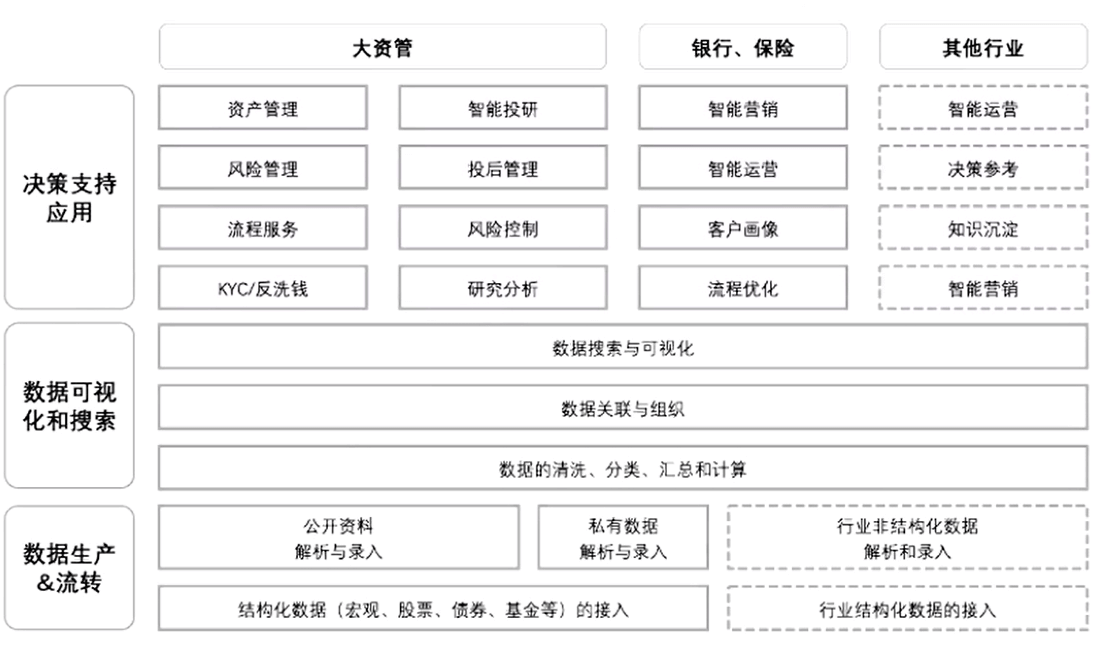
(一)证券资管行业
证券资管行业是效率至上、数据至上和决策分析最快的行业,所以合规流程、投研效率、成本负担等都是其非常重要的考量因素,人工智能能够为其提供一整套解决方案。以基金公司为例,基金公司内部有结构化和半结构化的数据,比如pdf研报、公告、新闻扫描等,以及采购的万得、同花顺里中的数据,先将这些海量数据源接入数据中台系统,在采集平台汇集,再进行加工,很多时候是使用上文提到的感知和认知技术把文字、段落、图表里的信息抽取出来,就像Google的搜索引擎一样非常方便地把所有数据解析出来。在这个领域阿博茨科技运用最成熟的案例在香港证券交易所,用阿博茨的系统审阅港交所上市公司公告,比如大量增发或分红公告等四五百页的文件。首先它能极大提升效率,也提升了服务满意度,因为在投资市场上,几天时间的合规审阅可能给大量投资人造成相应的损失,此外,它帮助企业来说完成数据沉淀和知识积累的过程,并满足其人力需求。
同时在面向直接投研的一些行业,可以应用智能数问系统,它是一个可视化的数据搜索平台。比如想知道科大讯飞近三年的净利润和营业收入,并对比不同公司,只需要在系统中系说一句话,它就可以把这句话翻译成机器查询语言,从数据库中调出数据,还通过大量的历史的研告学习让系统具备图像解析能力,直接绘制图表并输出,并且可以实时更新,从而更加高效直观。
(二)银行行业
银行业,尤其是信贷部门、风控部门,存在大量半结构化数据和固化流程,需要大量的人工参与。在这个领域上,阿博茨科技结合了多项技术,包括RPA的流程化自动机器人、机器视觉、自然语言处理和上文的数据搜索翻译引擎,来解决这些问题。
以财报录入为例,在信审部门拿到信息后,只需要拍照交给智能中台的RPA机器人,剩下所有抽取录入工作都能够自动完成,同时结合了人机接口,使专家可以录入模型公式,从而对财报进行勾稽关系校验,甚至是跨年份、跨报表、跨集团公司的数据校验。并且,结合数据抽取,银行可以进行表格和文本之间的数据比对,根据数据不一致,检查出某些公司的财报不合理或造假情况。
在贷后,系统可以帮助银行构建内外联动的风险管理体系。通过对外部信息,比如公众号推送、财经媒体的新闻资讯抓取,系统利用自然语言处理技术,对公司、人物、事件关系进行抽取。并且,系统可以处理企业内部的数据,比如发债、信贷合同和信审报告等,找到其与外部资讯的相关性,这是传统的舆情分析无法做到的,当把这些解析数据提供给企业内部时,就可以实现内外部联动,并通过知识图谱建立一个企业的360度的风险模型,包括产业链上下游、股东、实际控制人等,最终进行风险的预警和提示。此外,与传统舆情信息不同的是,该系统提供人机交互接口,让所有分析师研究员可以干预算法的优化,并且系统记录了研究员参与的标签评定,针对每次结果对其绩效进行加权,从而判断哪些人偏离比较严重,这样不仅可以积累大量样本,还能实现对每个人绩效的评定。
AI还能帮助实现智能运营和智能销售。传统上很多银行都有运营管理部或大数据中心,当内部运营时想知道某分行的营业收入和新增客户数,需要提交工单委托人进行整理、绘制和报送。而运用系统的翻译引擎、数据查询引擎和绘图引擎,就可以实现零代码拖拽,完成这些数据分析。并且它能对这些数据进行相应的积累和推荐,逐渐具备举一反三的能力,比如自动比较不同分行。随着使用人越多,机器也会变得越聪明。
(三)保险行业
保险行业的主要应用场景是智能理赔。保险理赔存在两个主要问题:第一是理赔成本高,因为它需要人工收集和录入信息,比如保单、发票、病例等,随着人力成本持续上升,录入成本会越来越高;第二是理赔时间长导致客户体验差,从而流失客户。而智能核赔首先通过技术识别,实现更高的准确率,并缩短原来数周的理赔时间变成一天,过程中客户只需要在自己的手机终端上对他所有的票据拍照,这一块被称为“人工+机器”的智能派单系统。如果机器识别超过100%置信度系统可以直接自动理赔,当置信度比较低,人工只需要去进行复核和抽检,同样大幅提高效率,降低成本。
(四)央国企行业
大型的国企央企的解决方案与上述类似,只是数据和业务不同。比如智能COO,可以对所有集团业务进行数据的图谱化,并提供搜索查询引擎,从而为企业的数据运营和领导决策提供智能版的数据驾驶舱。第二是对内部文件、研报进行解析。第三是财务自动化、法务自动化等业务场景。
总结下来,“数据工厂”类似于数据领域的智能富士康,覆盖数据的收集、提取、填报、搜索和最终的可视化,解决所有行业里与数据处理相关工作,实现数据赋能、工具赋能和业务赋能。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号