本文共字,预计阅读时间。
人脸识别是对客户进行身份验证的重要手段,目前已经广泛应用于各种互联网金融产品中。用户上传一张活体人脸图片和身份证照片做比对,以核验其身份。为了防止用户用照片、视频、面具等手段以假乱真,需要借助活体检测技术来判断其上传照片是否来自本人。按照技术手段,活体检测可分为动作活体检测、红外活体检测、静默活体检测等。其中,动作活体检测能够防范简单的照片攻击,它要求用户按照系统给出的随机动作指令完成眨眼、摇头、点头、张嘴等动作,完成后,系统从动作视频中抽取一张或多张活体图片上传到服务器进行人证核对(图一)。
活体检测涉及的技术包括人脸检测,人脸关键点定位,人脸追踪,姿态估计,图片分类等技术。目前,这些技术在业界已经相当成熟,完成动作活体检测只需整合这些技术即可。人脸检测和特征点定位,我们使用比较流行的MTCNN,它的检测精度和效率都比较高。MTCNN是多任务级联CNN的人脸检测深度学习模型,该模型中综合考虑了人脸检测和面部关键点检测。该模型包含3个级联的网络,P-Net用全卷积的方式在输入图像不同尺度上提取候选窗,这一步只是初步筛选,应当保证较高的召回;R-Net则对上一步选取的候选区域做更精细的过滤和边框调整;而最后一步O-Net则主要是预测特征点的坐标。所谓特征点,就是人脸嘴角、眼角、瞳孔中心和其他人脸轮廓等关键点,这些点的位置能够基本表示人脸的二维形状。基于特征点位置,我们可以定位到眼睛,嘴巴的位置,也可以用来估计人脸的姿态。因此,特征点的精准度是动作活体检测的关键。可以按照自己的需求对MTCNN做一些修改,比如修改O-Net预测的特征点数目等。

图一 动作活体检测算法
眨眼、张嘴动作的检测是基于对睁眼闭眼张嘴闭嘴等状态的检测,再结合一些时序的规则来完成的。人脸图片经过特征点对齐后,截取眼部和嘴部的区域,输入到训练好的神经网络模型,就可以判断眼睛嘴巴的闭合状态(图二)。由于人工标注样本数量有限,在训练过程中,为了提高模型的泛化能力,对输入图像做图像增广(Image Augmentation,如对图像进行水平翻转,对比度变化,添加随机噪声等)是必不可少的。
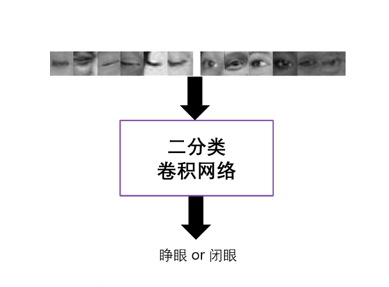
图二 眨眼检测算法流程
摇头、点头属于头部整体的运动,其关键是从视频中每帧人脸图片中估计头部姿态,包括yaw, pitch, roll三个姿态角。基于这些姿态角,结合一定时序规则可以完成摇头点头的检测。可以直接用图像特征或人脸特征点位置预测预测姿态角,也可先预测3D人脸模型的参数,而后通过3D人脸和2D人脸的关键点来推算出头部姿态(图三)。这一过程中,特征点检测不准确不稳定,关键特征点丢失都会影响姿态估计的准度,因此特征点检测的准确性至关重要。此外,可以结合人脸跟踪技术来解决人脸检测算法在人脸的偏转角度较大情况下失效的问题,同时可以提高速度。
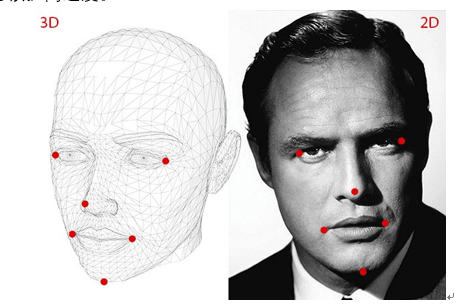
图三 3D人脸模型和2D图片
上述技术大多采用了深度学习模型,而活体检测模块一般是部署在用户端,如手机APP中。受移动端存储和计算资源的限制,我们需要对深度学习进行压缩。深度学习模型压缩方法包括参数修剪(parameter pruning)和共享、低秩分解(Low-rankfactorization)、迁移/压缩卷积滤波器和知识精炼(knowledgedistillation)、模型量化/二进制化(binarization)等。例如,使用谷歌公司的深度学习框架TensorFlow集成的模型量化的工具,可以将模型权重从浮点型量化成8位整形,模型大小可以大大减小。
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!首图来自图虫创意。
本文版权归原作者所有,如有侵权,请联系删除。首图来自图虫创意。

 京公网安备 11010802035947号
京公网安备 11010802035947号