本文共字,预计阅读时间。
NLP领域中,最细的粒度是词,词成句、句成段、段成章。很显然NLP问题从最基础的词出发。词本身是一种符号,不可量化不可用数值描述,需要把词映射成到数值向量空间(词嵌入embedding),word2vec就是其中一种。NLP中,语言模型(CBOW上下文做输入预测某个词本身、Skip-gram用某个词预测可能的上下文)的目的就是判断上下文词之间的相对位置是否接近真实情况,word2vec正式语言模型的产物,不要求语言模型最终效果逼近真实情况而是关心模型训练完成后得到的神经网络权重,这些权重就可以作为某个输入词的向量化表示。类似的,对于前后存在一定联系(局部)的序列,序列中最小单元无法直接用数值描述的问题,都可用word2vec进行预训练,得到最小单元的向量化表示。
得益于移动互联网的飞速发展,手机已成为人们日常生活中的一部分,订餐、购物、出行、线下支付、申请贷款都可以直接在APP上完成。在风控领域,APP上的操作行为对于预测欺诈和信用风险也是非常重要的数据源。传统的特征挖掘思路强依赖于人工经验。需要梳理APP不同页面下不同操作行为的含义,枚举和统计强业务相关强可解释性的高频【页面-事件组合】,通过有监督的方式留下符合可解释性、效果好、稳定的特征。整体上耗费时间,逻辑复杂易出错,而且操作序列间的相关性难以体现。使用word2vec预训练可以显著降低人工成本,找到序列间的局部相关性。下面介绍APP埋点行为挖掘的输入输出、网络结构、损失函数。
具体地,把【页面-事件】所有可能的组合看作词,删除极高频(类比停用词)、极低频(减少复杂度)的组合,余下的组合进行one-hot编码,使用skip-gram网络结构进行训练,V是过滤后所有【页面-事件】组合的总数,N为embedding size(N<<V),很显然,对于任意一个词经过onehot后向量空间是V(V中只有一个位置是1,其余都是0),经过embedding之后每个词都会被映射为N维,达到了降维的效果。
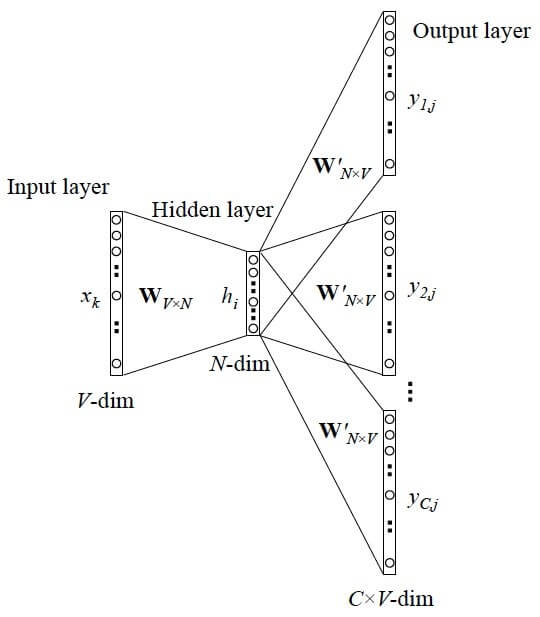
Word2vec本质上是非监督训练,但实际训练的实现方式仍然是有监督的,图中所示的损失函数是softmax,由于V很大,多分类问题计算复杂度很高。由此产生很多优化方法,sampled-softmax,只抽取一部分样本计算softmax;NCE-loss,把多分类问题转为采样后的多个二分类问题,正的样本通常由输入词前后固定长度窗口进行采样得到,负样本通常是按词频随机采样得到,越高频的词越易被采样到。
模型训练完成后,得到的embedding矩阵可以作为LSTM、一维CNN的初始化输入进行有监督训练,这可以加快收敛不需要重新随机初始化embedding矩阵;也可以直接使用embedding矩阵进行简单的特征生成,具体地,对于每一个样本都会有一个不定长的操作序列长度为S,序列中每个单元都对应一个N维的向量,这样可以得到一个[S, N]的矩阵,可按axis=0求均值、最大值、最小值、和、标准差。
文/天机模型算法团队
非常感谢您的报名,请您扫描下方二维码进入沙龙分享群。

非常感谢您的报名,请您点击下方链接保存课件。
点击下载金融科技大讲堂课件本文系未央网专栏作者发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文为作者授权未央网发表,属作者个人观点,不代表网站观点,未经许可严禁转载,违者必究!
本文版权归原作者所有,如有侵权,请联系删除。

 京公网安备 11010802035947号
京公网安备 11010802035947号